Plutoman wrote:How would using pi make it more random? The sequences, as the number goes on, would have the EXACT same properties as the random numbers brought in. And, also, the fact that a sequence will come up more the more numbers have come in, is in itself a fallacy. If you center on one section, the numbers will appear randomly spread out. Taken as a whole, you have sections that will repeat, but you have that in normal sections, too.
That's not really true. If you look at how random.org generates random numbers, it is measuring some type of natural phenomenon and running it through some type of multi-variable function. However, as a general rule regarding a continous function that has an equal probability that the next value will be either higher or lower, the most likely next value is the current value. I suspect, but don't know for sure, that something like that is going on with the numbers generated by random.org. Now I know there are natural phenomenon that don't follow a continous path, and so it might be possible that they are transforming their measurements to correct for it, but that would involve something like application of principles from quantum mechanics (and even there, you have people going back to a continous "string" model to explain what's going on...) I don't know for sure, but I'm skeptical. I'd say there's a reasonably good chance that random.org could just as well fill a file using a time-series of the fractional share price of Google stock as what they are doing with radio waves....
And I think we have a different view of what CC is doing with it's random.org file. To me, it sounds like they have one file of dice lines, and once they get to the end, they start back over from the beginning of the file. That doesn't mean you'll get the same dice every game, because they read out of the file sequentially for every game that is being played... today you might play a game using lines 379-450. Tomorrow, you might play using lines 110,000-110,089. And for the game that you play once a day, your going to be all over the map. That would be just like taking a fixed irrational number. Yes there will be repeating chains in that as well, but they will repeat randomly.
It's random numbers, and regardless of complaints, it IS random. Pi is not random. These numbers, regardless that they are pulled from a file, are randomly produced, and just saved. Pi never changes, these numbers are different each and every time.
The only reason the number are differnt every time is because you are playing your game at a different point in the file, as I read it. I could be wrong here though.
You also have to consider odds. These numbers are produced for many, many sites. And even if you only take this one site into consideration, many streaks are going to happen for people every day. The way the dice are read, it is reading multiple turns per second, so it's not just going against you in a row. It's also reading others turns, at the same time.
Yes, this is a saving grace. But the more I've played, the more I question whether there is actually that type of volume on the site. 850,000 lines of dice per day is about 11 lines per second. Yes, that sounds fast, but there are probably times where that number drops significantly.
Going back to one thing you said:
And, also, the fact that a sequence will come up more the more numbers have come in, is in itself a fallacy. If you center on one section, the numbers will appear randomly spread out.
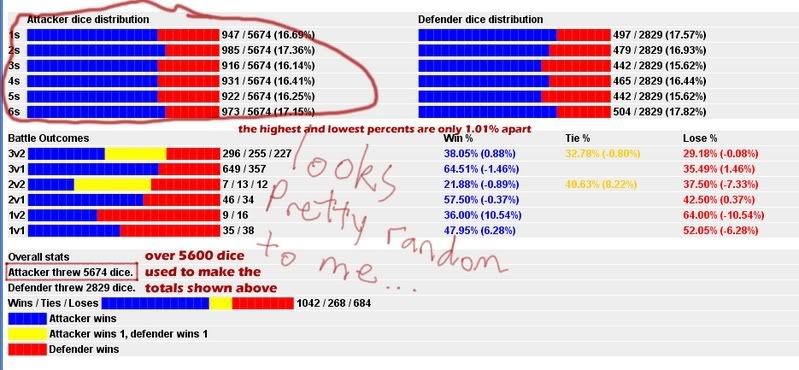
If I tell you that the next value in a series has an equally likely chance to be higher or lower than the current value, your best guess for the next number is the number itself. Based on the range of possible values you are looking at, this might be just a nominal blip on the probability distribution, but if I chop that up into series of 3 and 2 consequtive measurements, you would expect to have more repeats in the "3 series" than the "2 series than would be produced by a completely random string. There should be a way to test the data file for this... I'l have to think about it a bit....
The statistical ideal would be to have 6 out of 216 rolls be a tripple repeat. And to have 6 out of 36 be a doubt repeat. You could take a binary function of the absolute value of the difference of all A digits in every row over the number of rows, and a binary function of the absolute value of the difference of all D digits in every row over the number of rows, and compare them to the respective ideals... I think that would settle the question. So whose got the dice file...

](./images/smilies/eusa_wall.gif "Brick wall")